MapReduce分布式计算前期准备
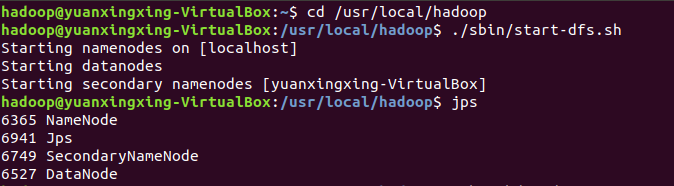
1.启动Hadoop
1 | cd /usr/local/hadoop |
2.在桌面新建word.txt文件,并使用gedit编辑器在其中添加英文单词
1 | cd ./桌面 |


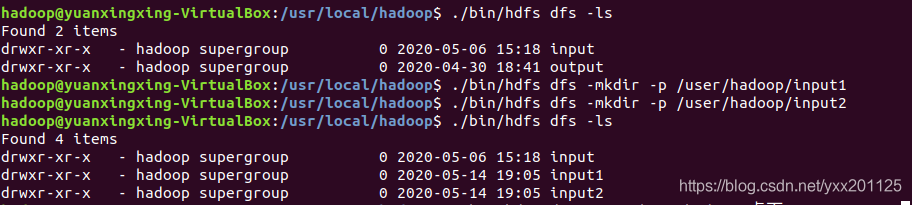
3.在hdfs目录下创建input1和input2文件夹
1 | ./bin/hdfs dfs -ls |
4.将桌面上的word.txt文件拷贝到input1目录下
1 | ./bin/hdfs dfs -put /home/hadoop/桌面/word.txt input1 |

5.将/usr/local/hadoop/etc/hadoop目录下的所有.xml文件拷贝到input2目录下
1 | ./bin/hdfs dfs -put ./etc/hadoop/*.xml input2 |
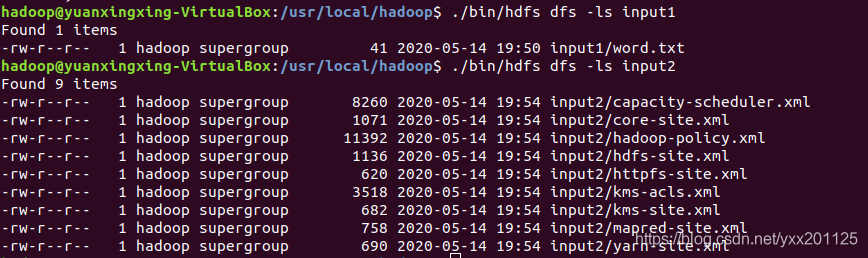
6.检查拷贝是否成功
1 | ./bin/hdfs dfs -ls input1 |
MapReduce的圆周率计算方法
1.查看mapreduce目录所在位置
1 | cd /usr/local/hadoop/share/hadoop/mapreduce |
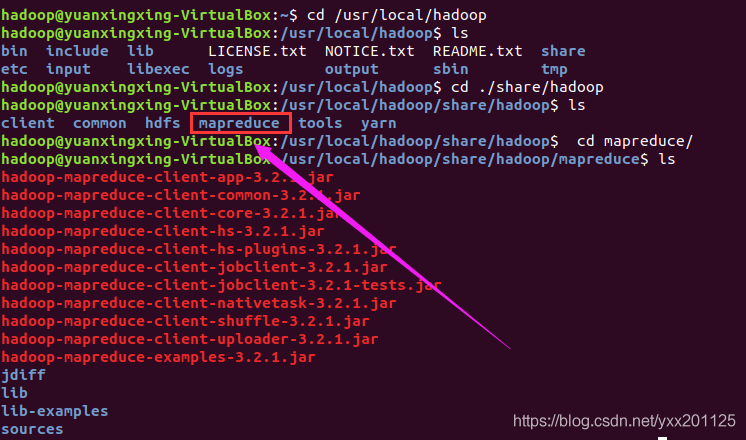
2.切换目录,通过使用hadoop-mapreduce-examples-3.2.1.jar
包计算pi的值
1 | cd /usr/local/hadoop |
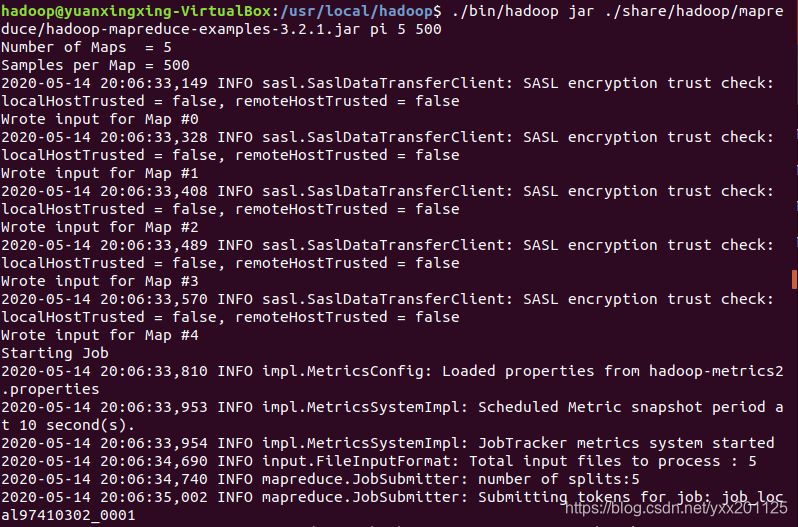 3.查看相应的计算结果
3.查看相应的计算结果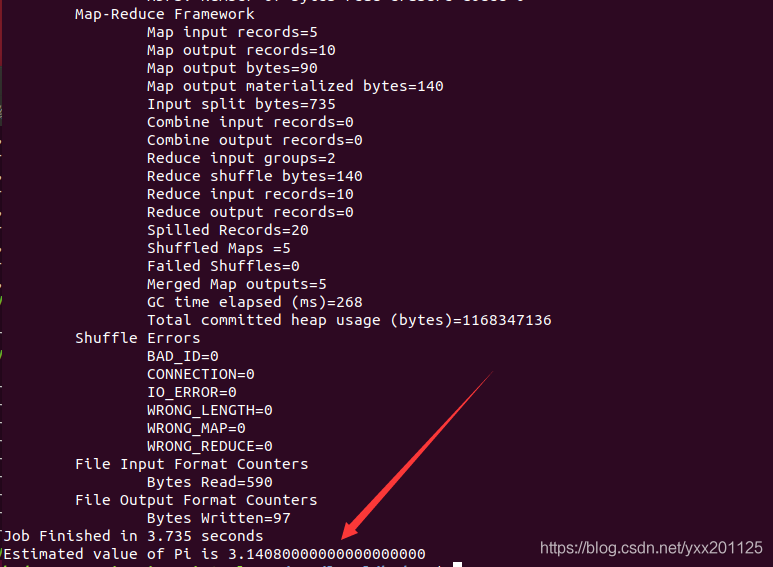
MapReduce的Wordcount计算方法
1.查看input1目录下word.txt文件内容
1 | ./bin/hdfs dfs -cat input1/word.txt |

2.通过使用hadoop-mapreduce-examples-3.2.1.jar
包统计单词个数,并保存于output1目录下
1 | ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount input1 output1 |
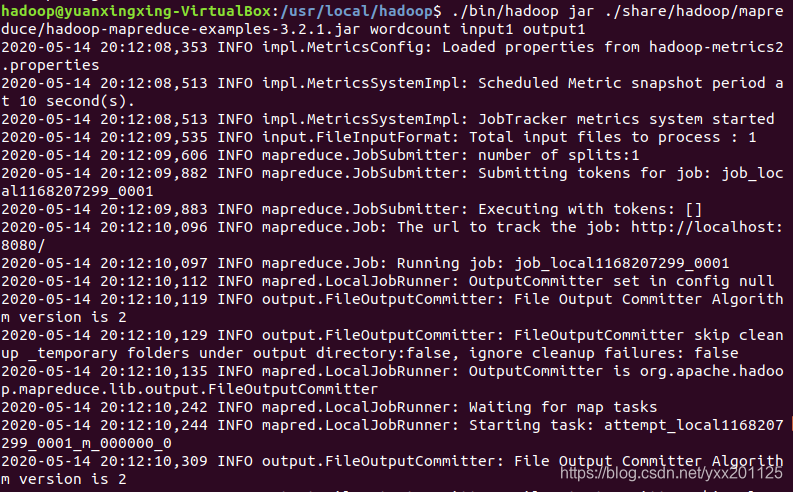
3.查看MapReduce的Wordcount计算结果
1 | ./bin/hdfs dfs -ls |
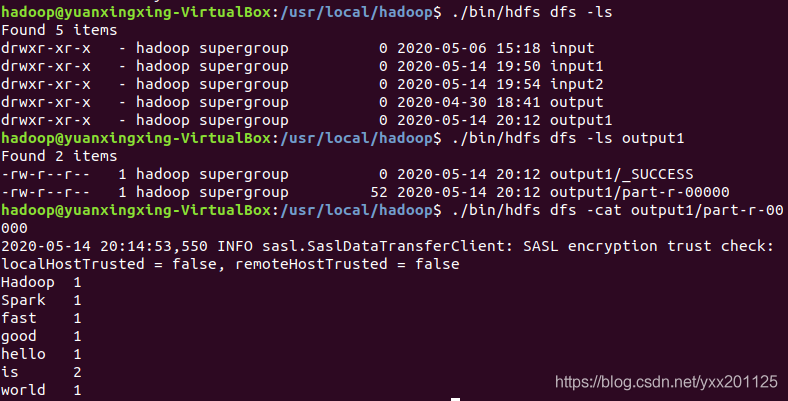
MapReduce的正则表达式匹配计算方法
1.使用上传在input2目录中的XML文件,并使用MapReduce相应计算程序,完成正则表达式计算,统计该.xml文本中满足’dfs[a-z.]+ ’匹配规则的字符
1 | ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input2 output2 'dfs[a-z.]+ ' |
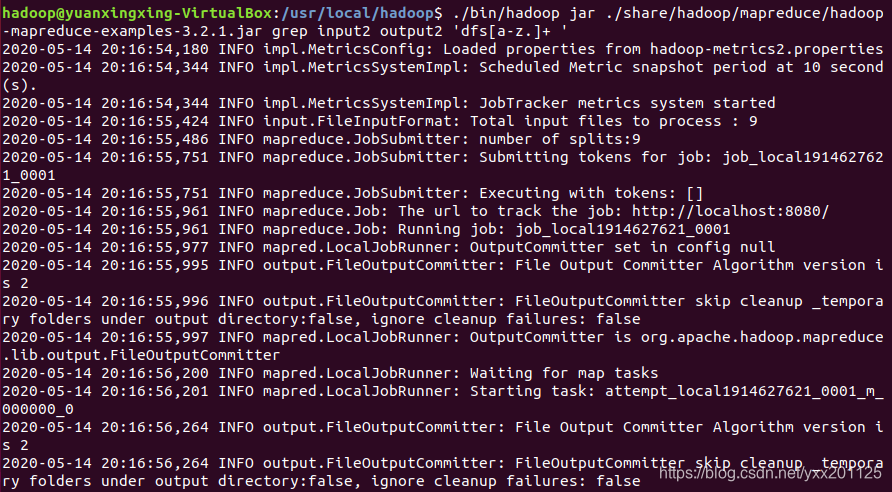
2.查看output2目录是否创建成功
1 | ./bin/hdfs dfs -ls |

3.查看output2目录
1 | ./bin/hdfs dfs -ls output2 |

4.查看MapReduce的grep正则表达式匹配计算结果
1 | ./bin/hdfs dfs -cat output2/part-r-00000 |

关闭hdfs
1 | ./sbin/stop-dfs.sh |

本次MapReduce分布式计算实例:pi程序、wordcount程序、grep程序演示到此就结束了,各位可爱们在实验过程中一定要注意细节哦,如果博客中有问题,欢迎各位大神们指点迷津