准备工作
Ubuntu下安装IDEA
1.下载地址: https://www.jetbrains.com/idea/download/#section=linux.
小编选择的版本是ideaIU-2019.3.3.tar.gz
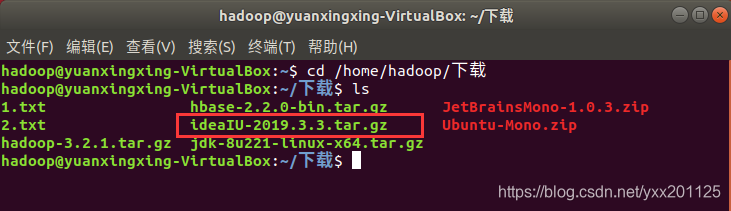
2.查看下载
首先切换到下载目录
要注意该处的hadoop,为当前用户名
汉化版代码如下:
1 | cd /home/hadoop/下载 |
未汉化版:
1 | cd /home/hadoop/Downloads |
3.将压缩包解压到/opt目录下
注意压缩包的版本号
1 | sudo tar -zxvf ideaIU-2019.3.3.tar.gz -C /opt |
4.进入安装位置并启动IDEA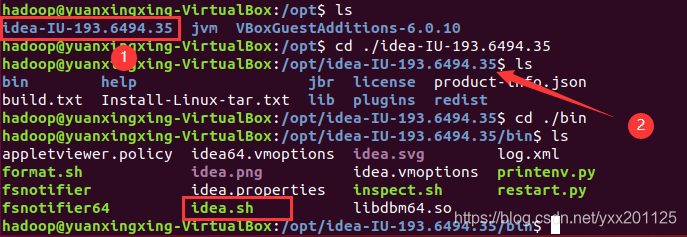
打开相应IDEA的bin目录,idea.sh是IDEA的启动文件,我们可以通过终端运行idea.sh文件启动 IDEA
5.测试安装是否成功
(1)新建工程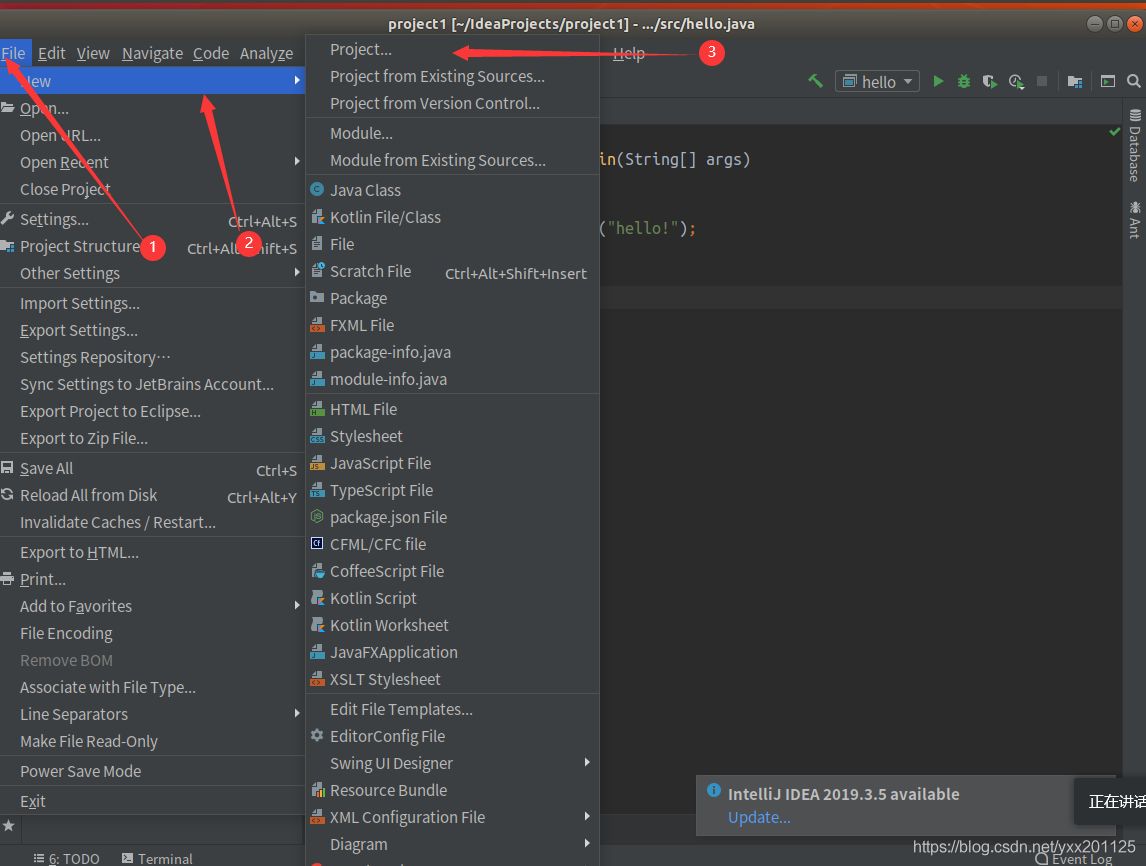
在弹出新建工程的界面选择Java,接着选择SDK,一般默认即可,点击“Next”按钮,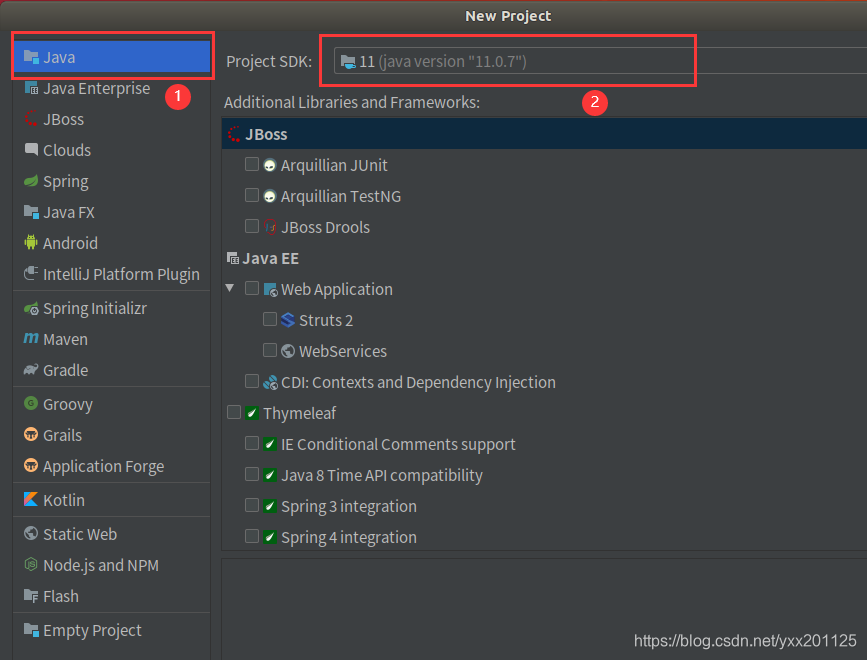
在弹出的选择创建项目的模板页面,不做任何操作,直接点击“Next”按钮。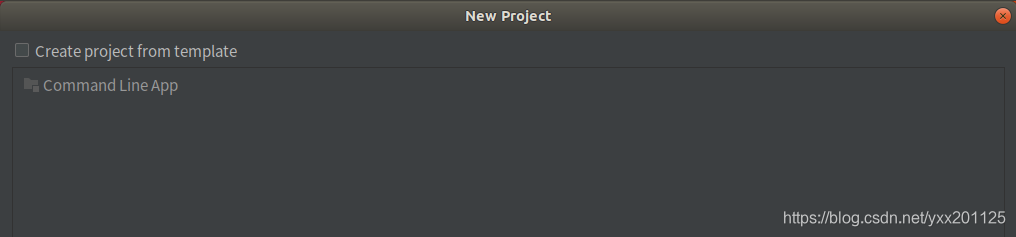
输入项目名称,点击Finish,就完成了创建新项目的工作,小编所建的项目名称为:project1。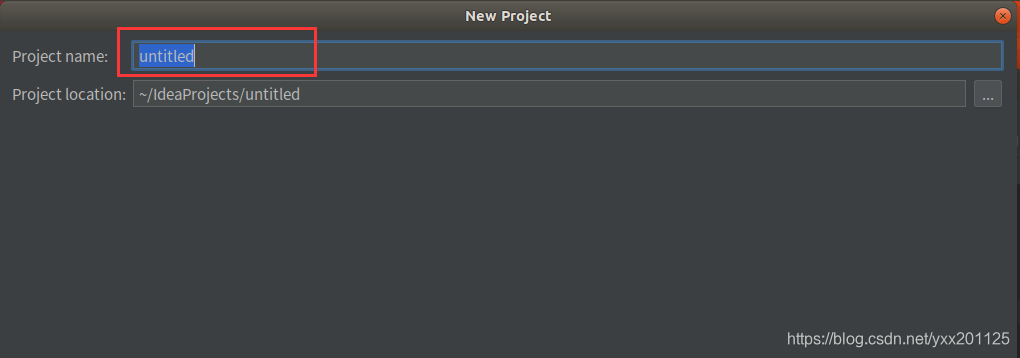
(2)新建java class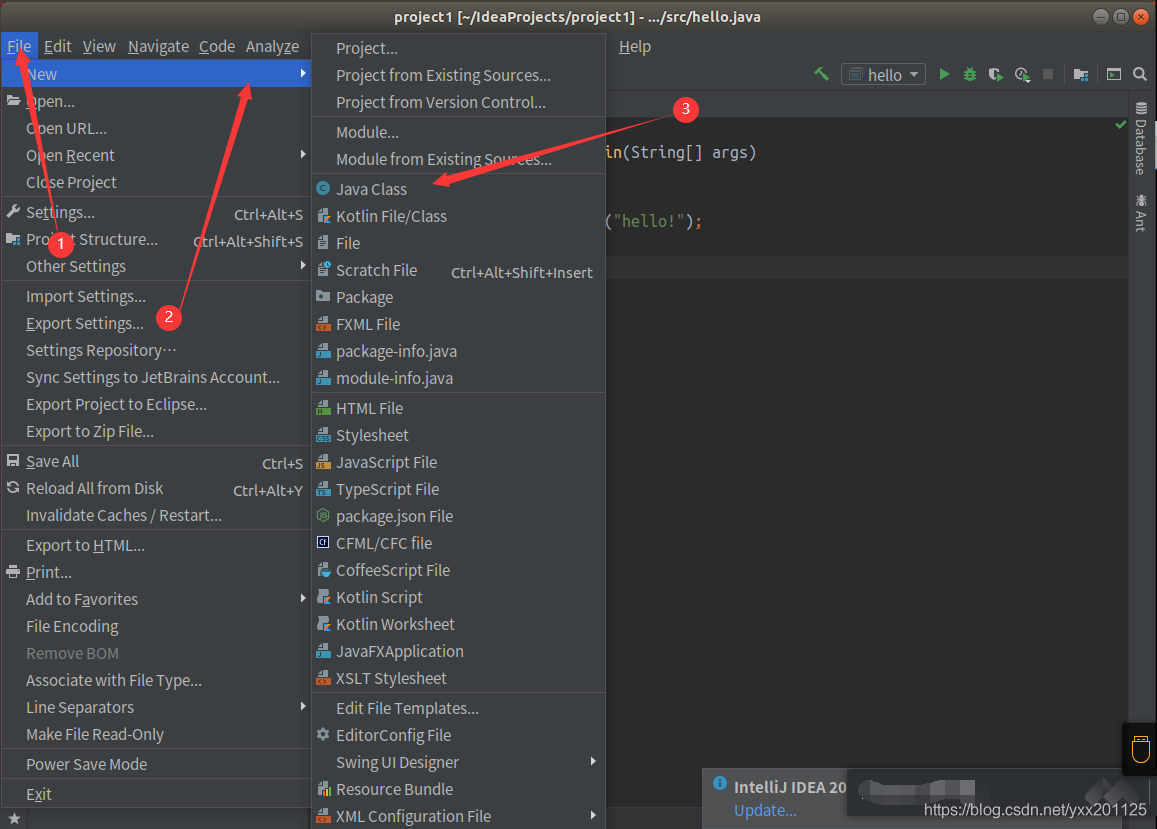
(3)测试运行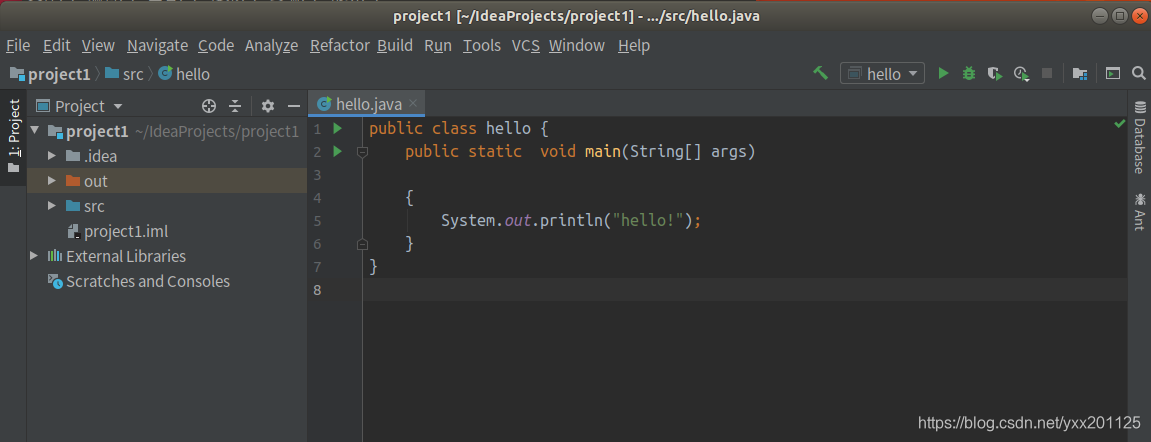
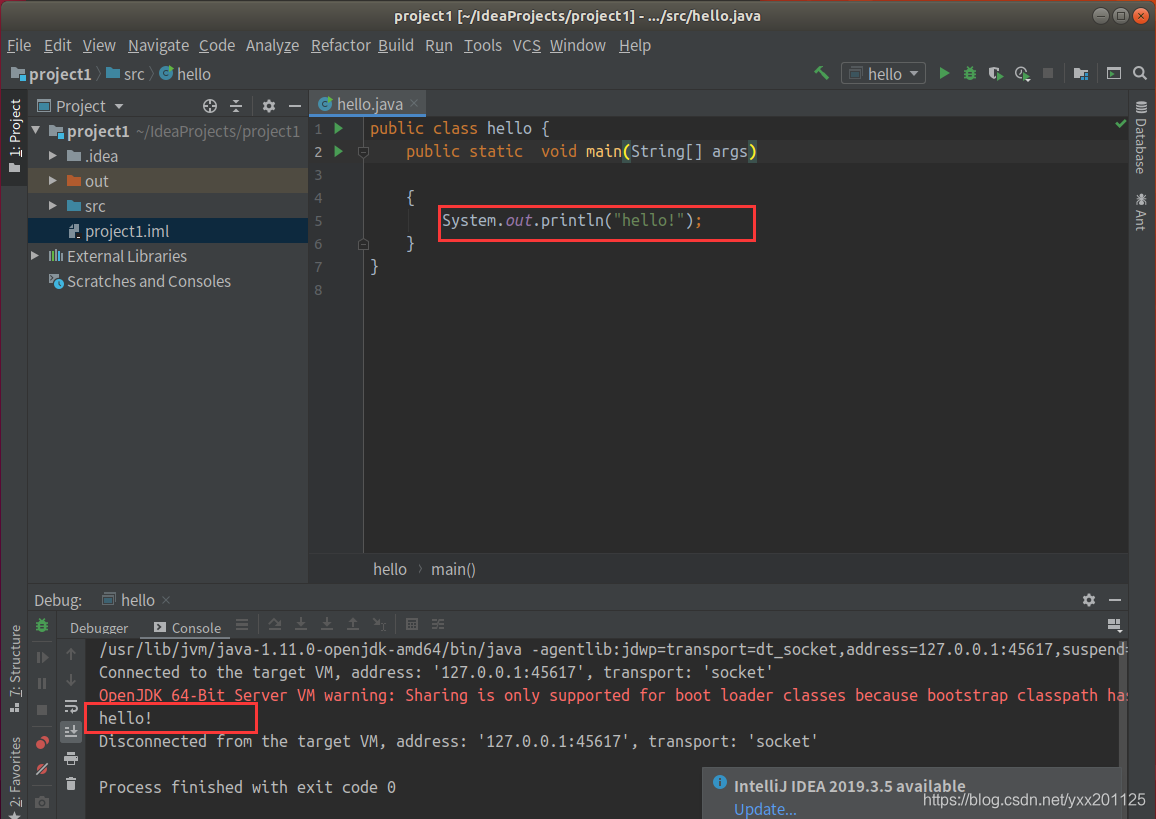
若成功输出相应的结果,则证明安装成功。
到此Ubuntu下安装IDEA就完成了
相应包的导入
1.在idea新建一个Java Project,并import需要的Hadoop JAR包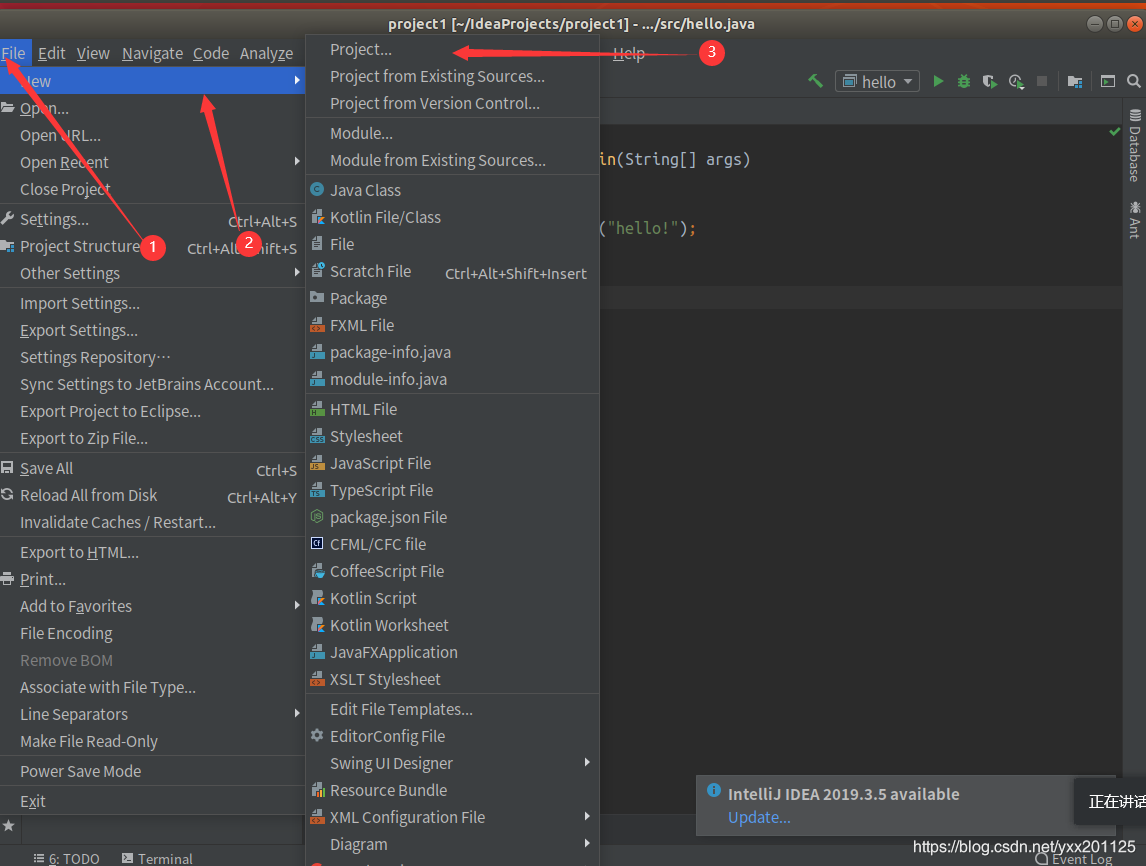
在弹出新建工程的界面选择Java,接着选择SDK,一般默认即可,点击“Next”按钮,
在弹出的选择创建项目的模板页面,不做任何操作,直接点击“Next”按钮。
输入项目名称,点击Finish,就完成了创建新项目的工作,小编所建的项目名称为:Java Project。
2.添加jar包,和Eclipse一样,要给项目添加相关依赖包,否则会出错。点击Idea的File菜单,然后点击“Project Structure”菜单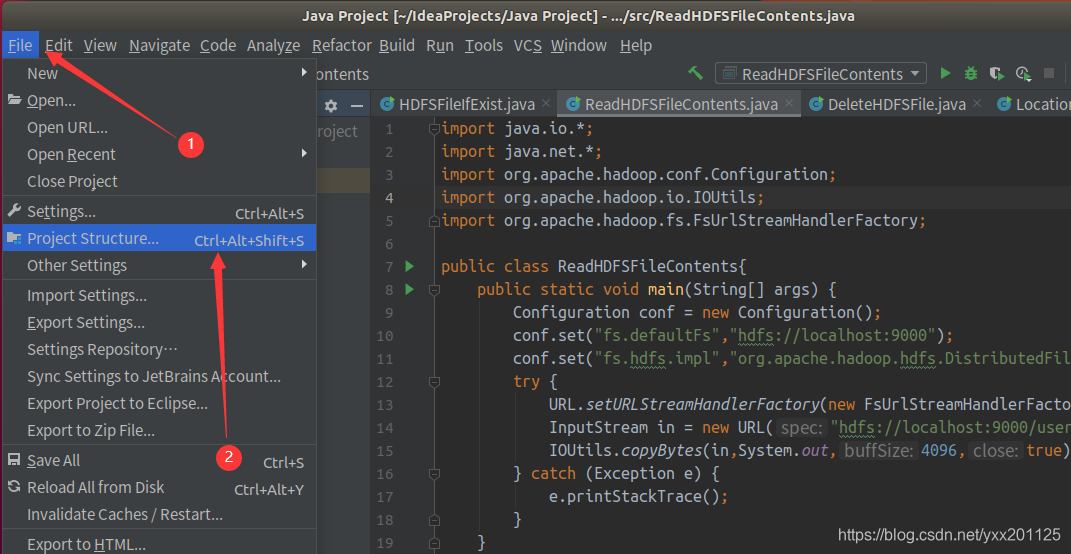
依次点击Modules和Dependencies,然后选择“+”号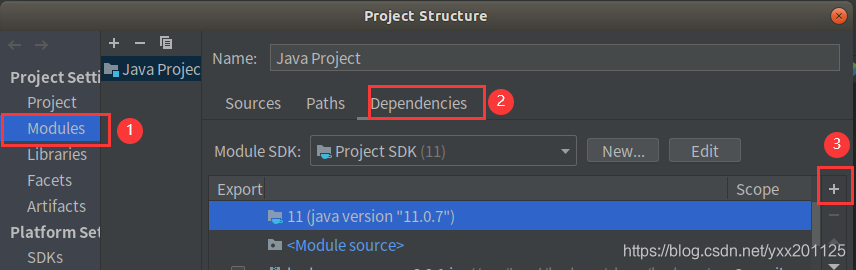
3.选择hadoop的包,我用得是hadoop3.2.1。把下面的依赖包都加入到工程中,否则会出现某个类找不到的错误。
1 | (1) /usr/local/hadoop/share/hadoop/common目录下的hadoop-common-3.2.1.jar和hadoop-nfs-3.2.1.jar。 |
若不添加(5)对应的hadoop-hdfs-client-3.2.1.jar包,可能会报如下错误:
4.将导入的包apply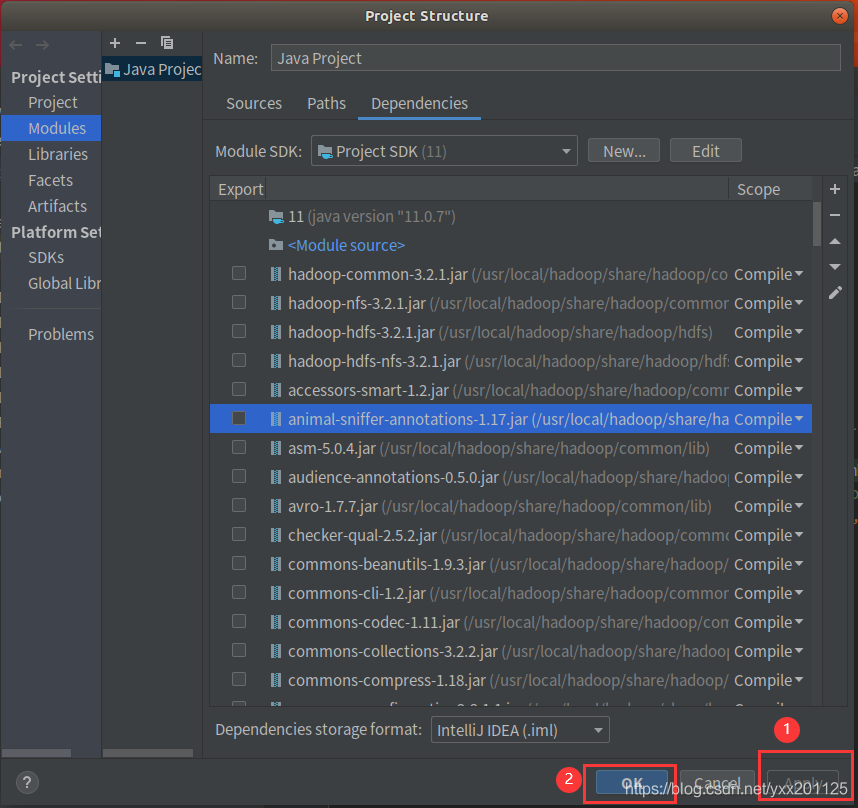
启动Hadoop
1 | cd /usr/local/hadoop |

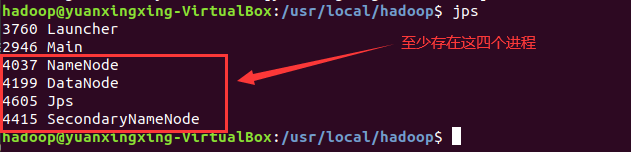
查看进程
1 | jps |
从本地拷贝文件到HDFS
1.新建java class
2.在当前用户的桌面创建一个1.txt,作为传输文件进行测试。
1 | import java.io.BufferedInputStream; |
警告信息可忽略
成功拷贝则运行输出success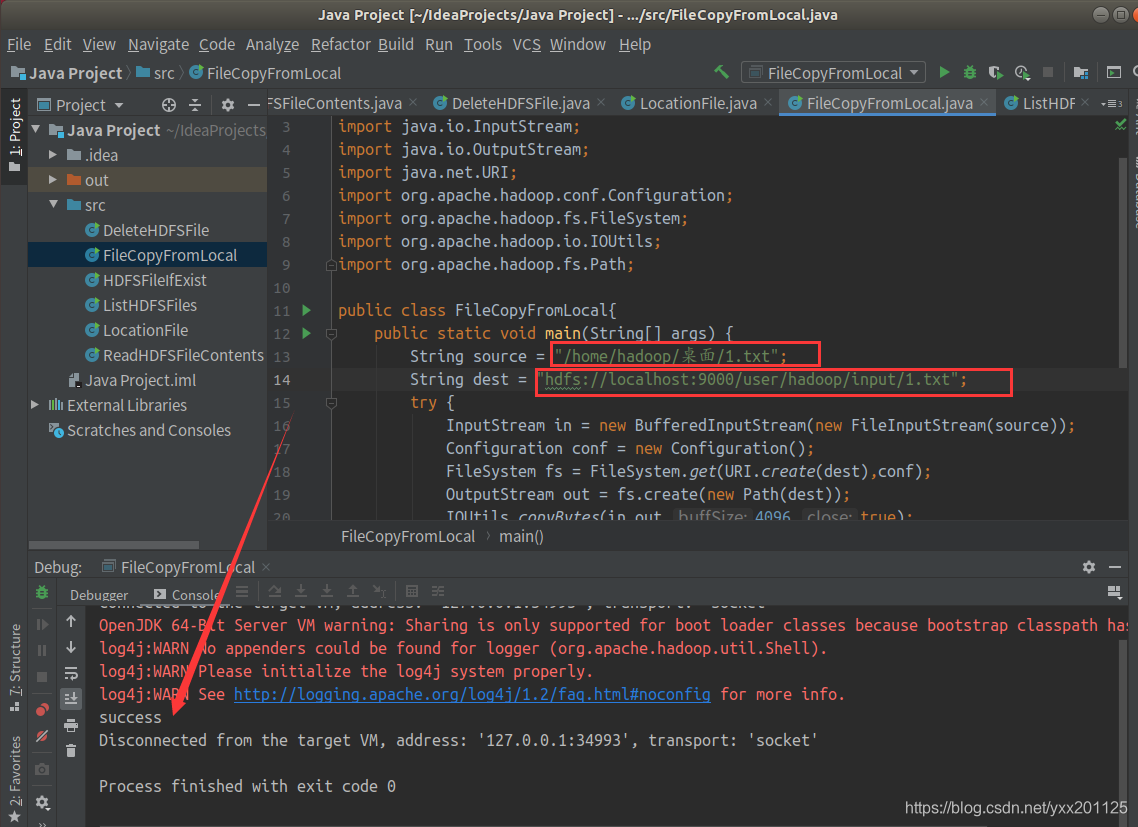
判断HDFS目录中对应文件是否存在
1.新建java class
2.查看1.txt,作为传输文件是否存在
1 | import org.apache.hadoop.conf.Configuration; |
存在则运行输出exists!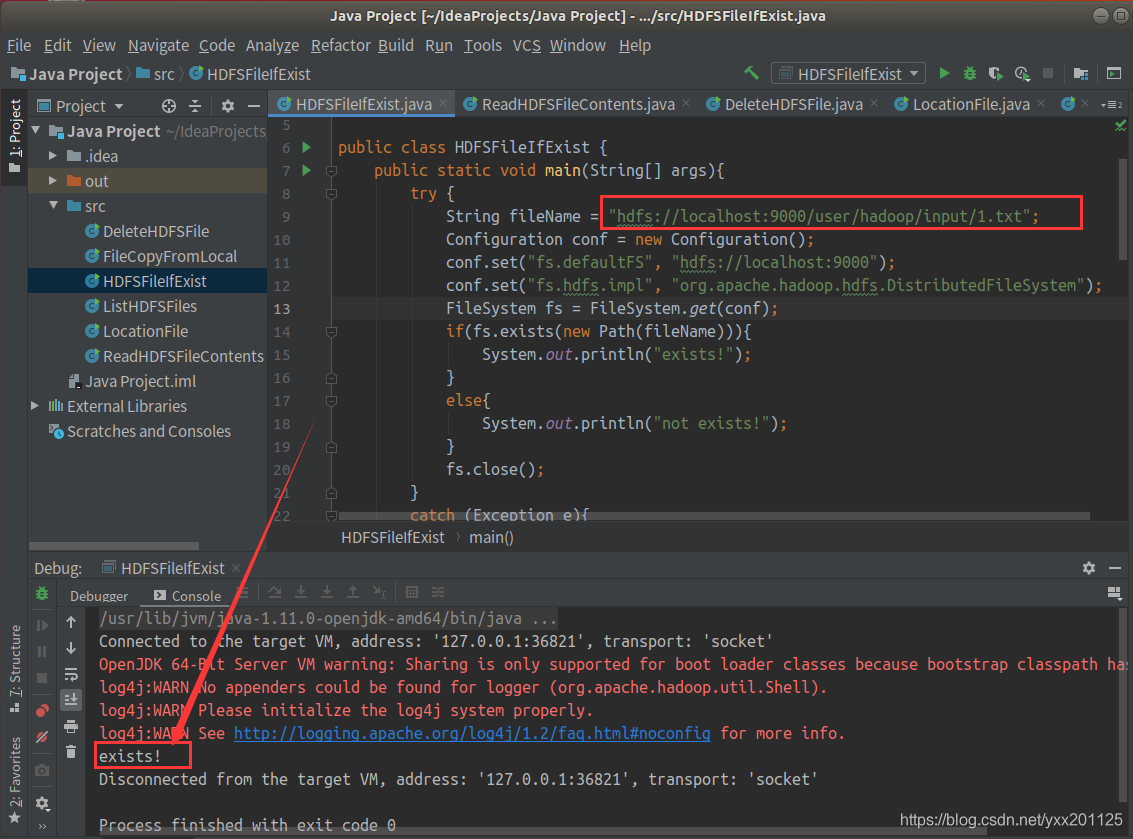
列出HDFS目录中相应文件信息
1.新建java class
2.查看/user/hadoop/input目录内容
1 | import java.net.URI; |
显示如下: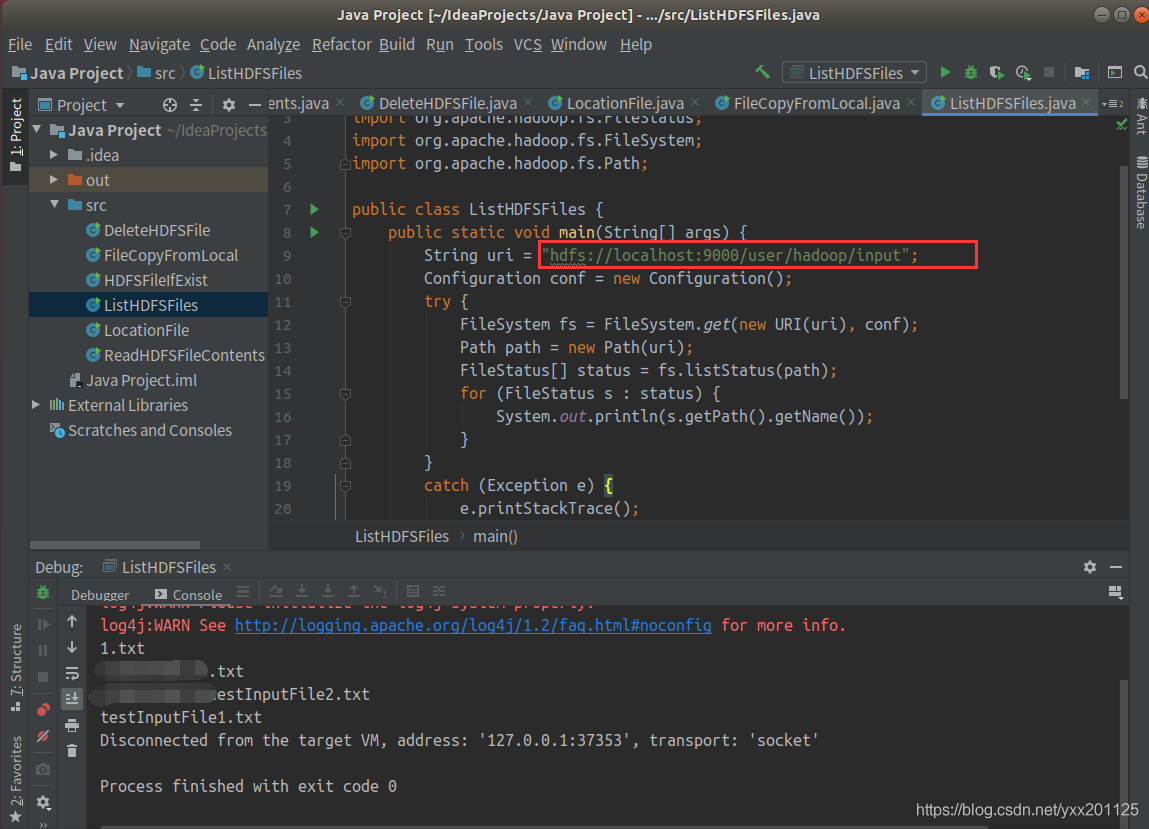
读取HDFS目录中相应文件内容
1.新建java class
2.查看input目录下1.txt内容
1 | import java.io.*; |
输出文件内容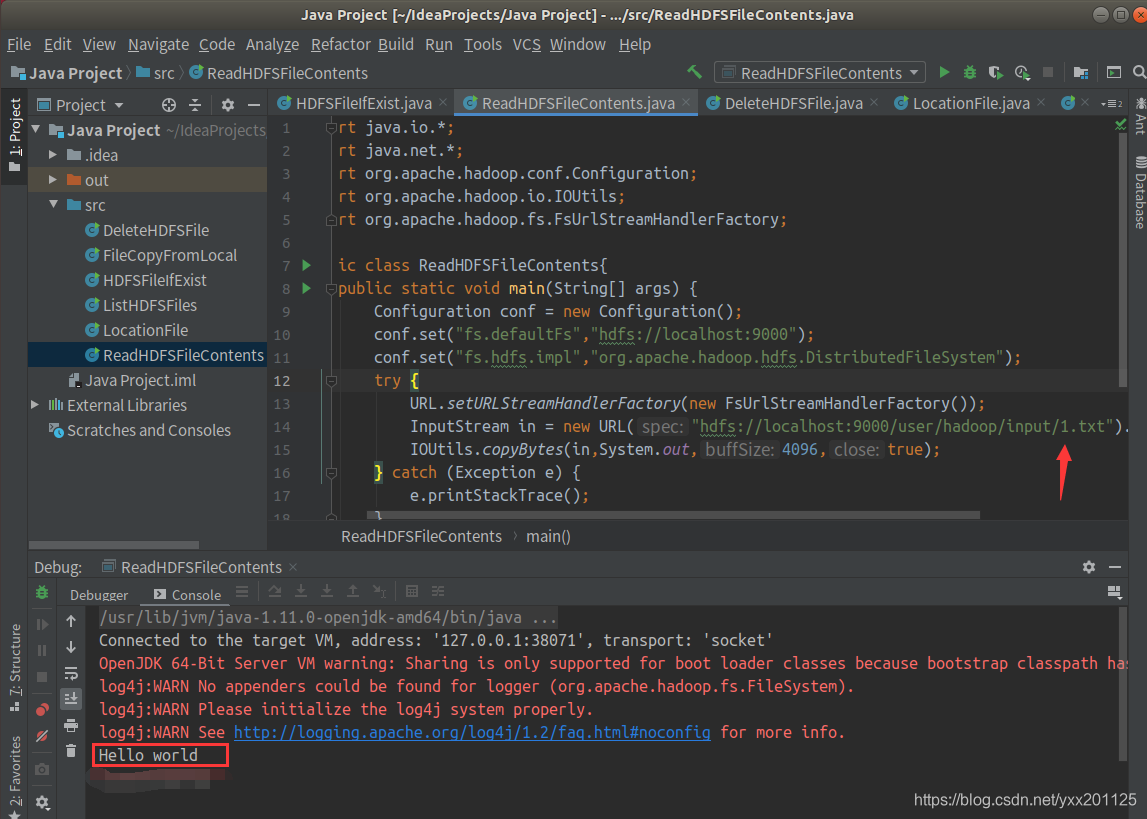
读取HDFS相应文件的BLOCK信息
1.新建java class
2.查看input目录下1.txt所对应的block信息
1 | import java.net.URI; |
输出block信息则成功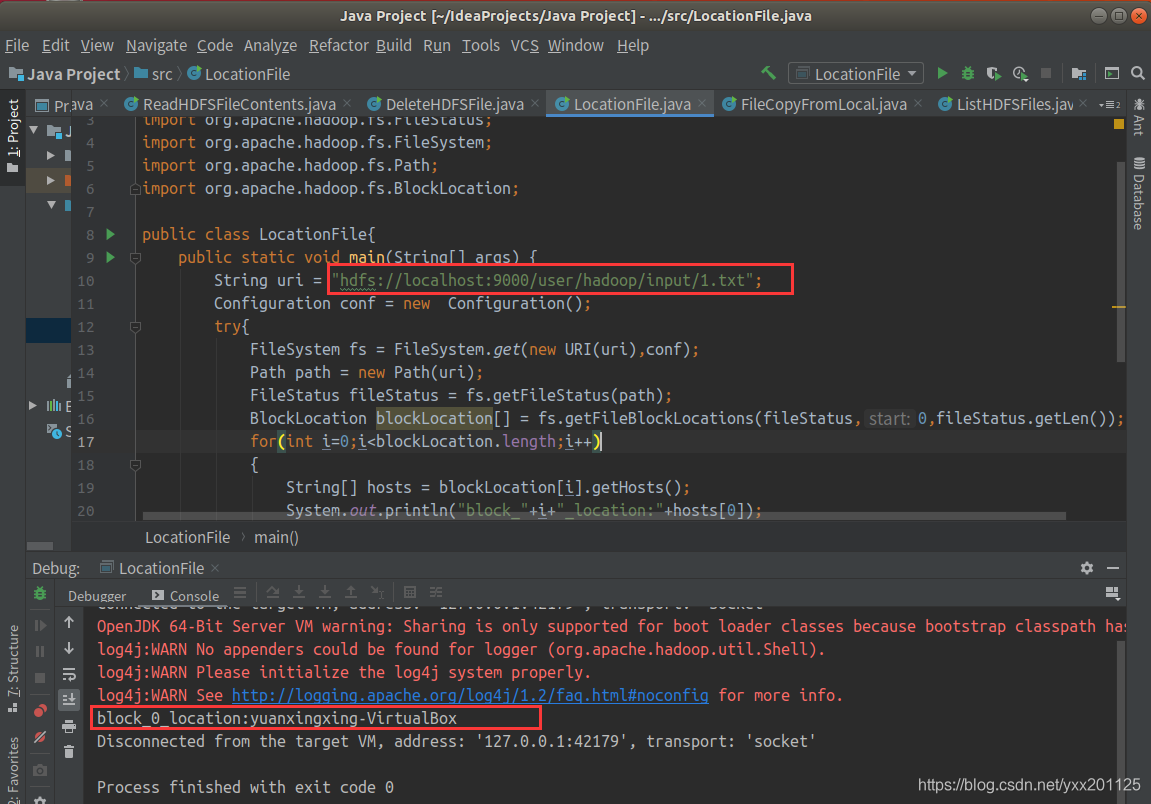
删除HDFS目录中相应文件
1.新建java class
2.删除input目录下1.txt文件
1 | import org.apache.hadoop.conf.Configuration; |
删除成功则返回ture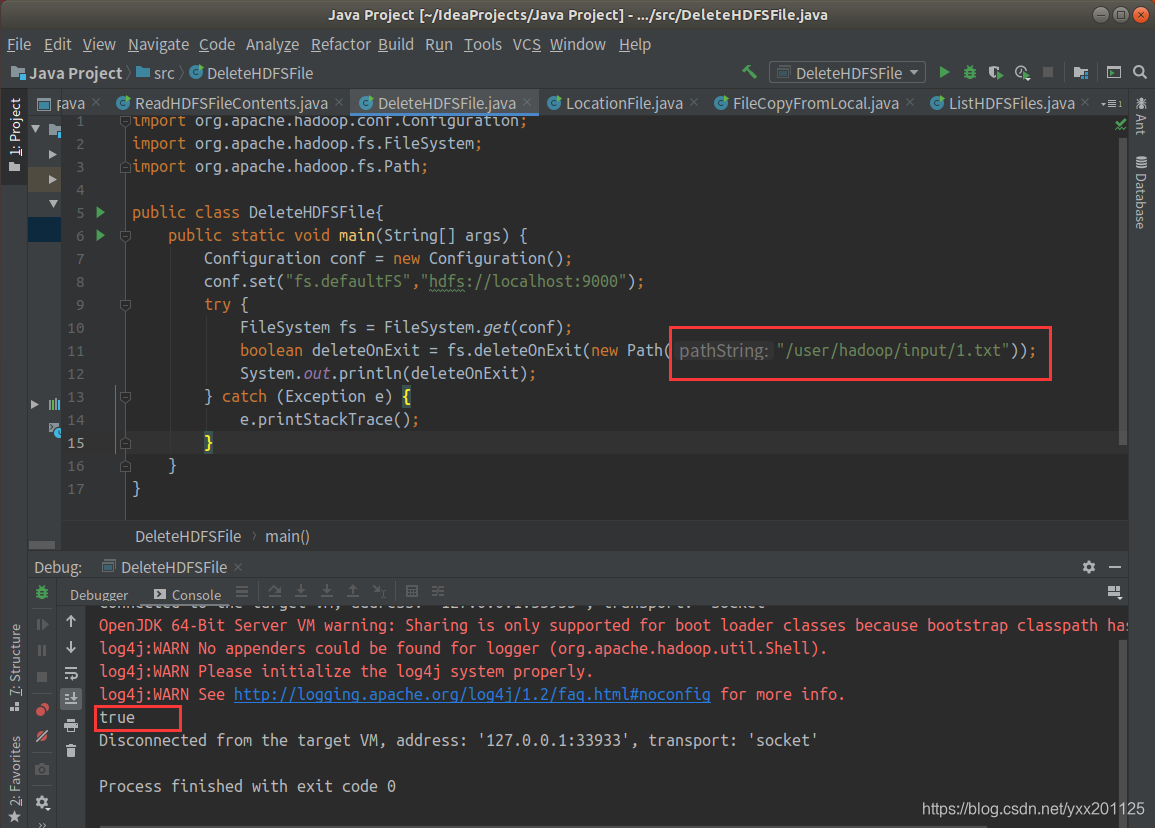
关闭hadoop
1 | ./sbin/stop-dfs.sh |

至此HDFS分布式文件系统的JAVA数据访问方法,就结束了。各位可爱们在实验过程中一定要注意细节哦,如果博客中有问题,欢迎各位大神们指点迷津。