Spark的安装与配置
Spark的下载
Spark官网下载地址: http://spark.apache.org/downloads.html.
因为前期已经配置了Hadopp,所以在Choose a package type后面需要选择Pre-build with user-provided Hadoop,然后单击Download Spark后面的without-hadoop压缩包即可,下载的文件会被默认保存在”/home/hadoop/下载”目录中。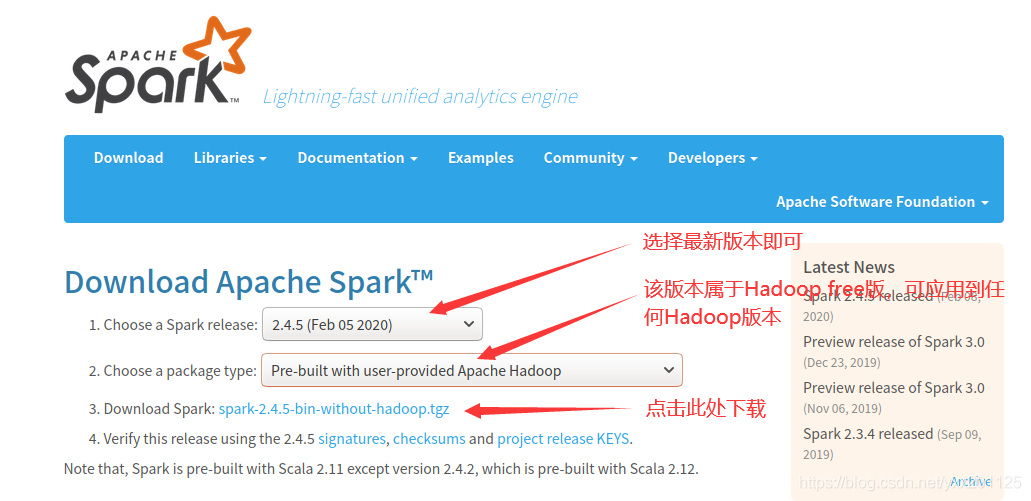
选择推荐的镜像即可下载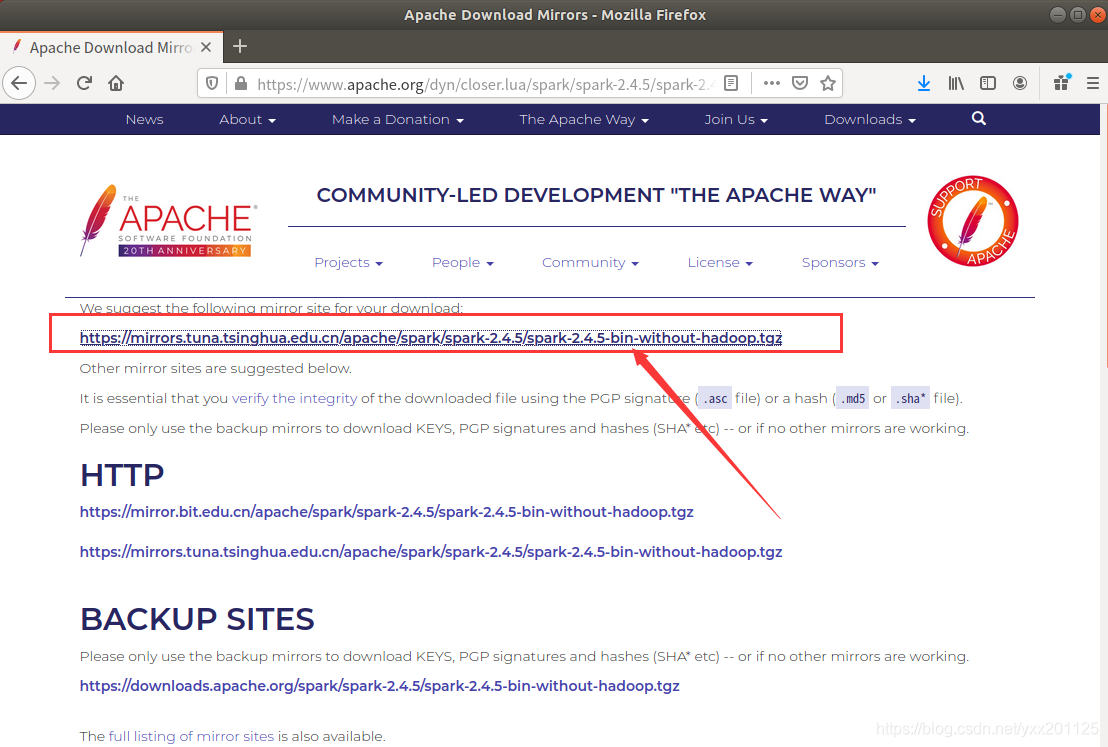
1 | sudo tar -zxf ~/下载/spark-2.4.5-bin-without-hadoop.tgz -C /usr/local/ |
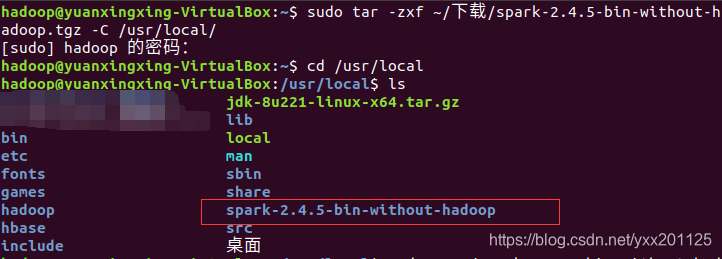
为了方便目录的查看等,将解压后的文件重命名为spark
1 | cd /usr/local |

为文件授予权限,避免遇到文件无法创建等问题,注意更改为当前用户名
1 | sudo chown -R hadoop:hadoop ./spark # hadoop是当前登录Linux系统的用户名 |

Spark的配置
修改Spark的配置文件spark-env.sh
安装文件解压后,需要修改Spark的配置文件spark-env.sh,首先可以先复制一份Spark安装文件自带的配置文件模板,命令如下:
1 | cd /usr/local/spark |

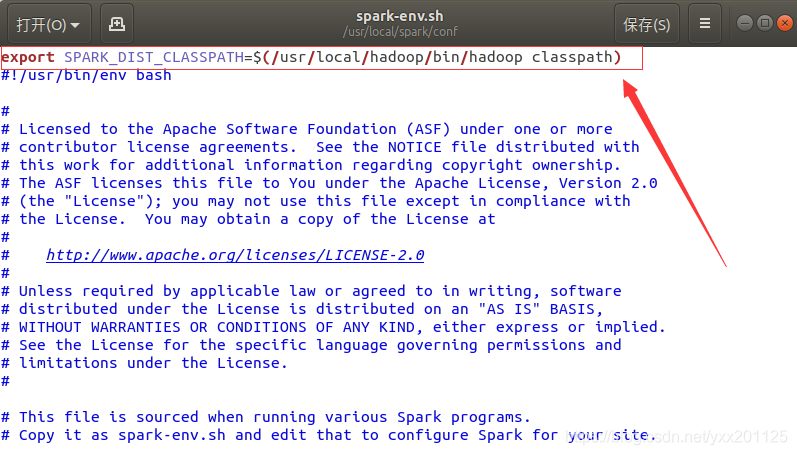
使用gedit编辑器打开spark-env.sh文件进行编辑,在该文件的第一行添加一下配置信息:
1 | export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath) |
验证Spark安装是否成功报错:/usr/local/spark/bin/spark-class: 行 71: /usr/lib/jdk/jdk1.8.0_221/bin/java: 没有那个文件或目录(详情可见小编的上一篇博客: here.)
解决方式:
jdk找不到路径问题,/usr/local/spark/conf/spark-env.sh文件中添加如下的 Java环境信息(可加到文本末尾,注意jdk版本号),直接配置修改文件spark-env中export (导入)jdk的路径即可。
1 | export JAVA_HOME=/usr/java/jdk1.8.0_221 |
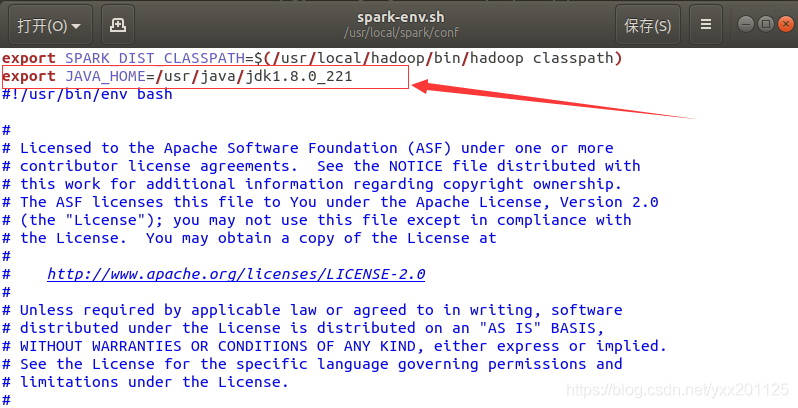
有了上述的配置信息后,Spark就可以把数据存储到Hadoop分布式文件系统HDFS中,也可以从HDFS中读取数据。如果没有配置上面的信息,Spark就只能读写本地数据,无法读写HDFS中的数据。
配置完成后,就可以直接使用Spark,不需要像Hadoop那样运行启动命令,通过运行Spark自带的实例,可以验证Spark是否安装成功,命令如下:
1 | cd /usr/local/spark |
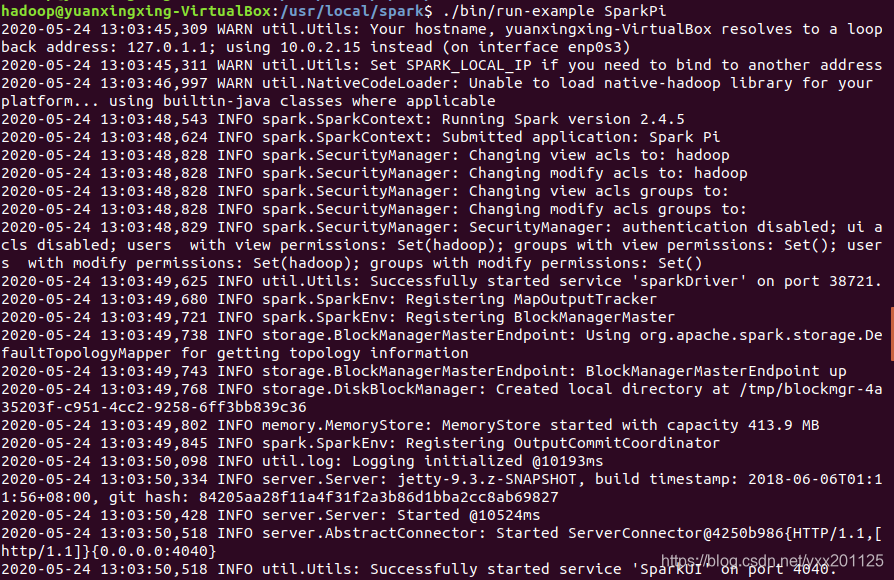
执行时会输出很多屏幕信息,不容易找到最终的输出结果,为了从大量的输出信息中快速找到我们想要的执行结果,可以通过grep命令进行过滤。
1 | bin/run-example SparkPi 2>&1 | grep "Pi is roughly" |

启动Spark shell
1 | cd /usr/local/spark |

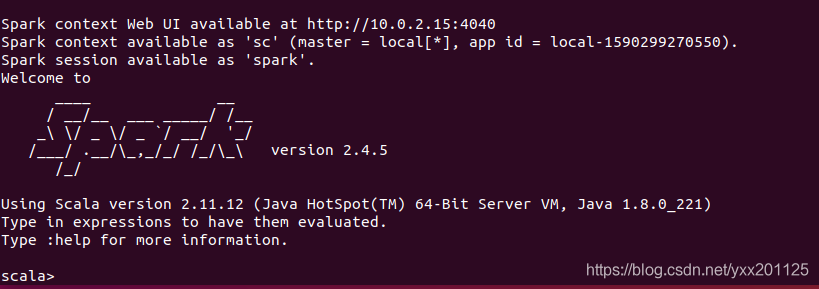
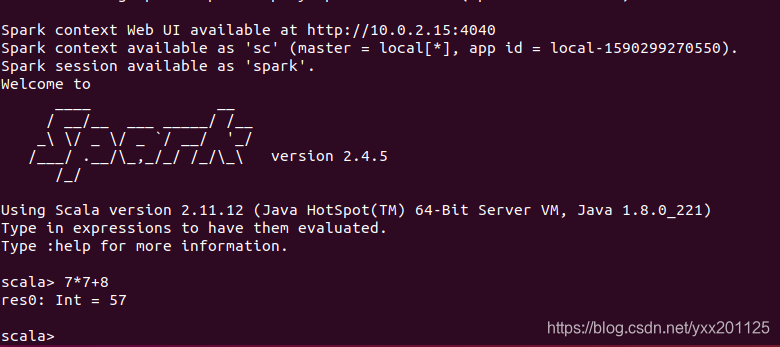
在Spark shell中进行测试
1 | scala> 7*7+8 |
关闭shell
1 | scala>:quit |

至此,Spark计算环境的搭建就结束了,如果博客中有问题,欢迎各位大神们指点迷津